

SPASM
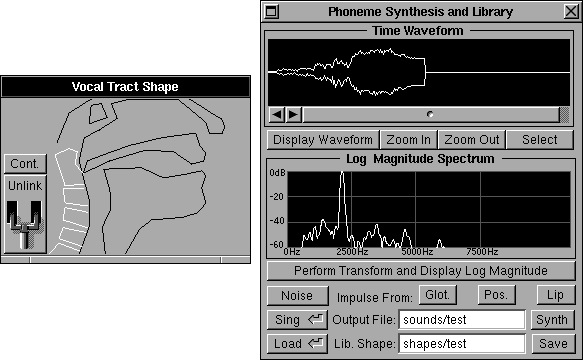
Singing Physical Articulatory Synthesis Model (SPASM), developed at the Center for Computer Research in Music and Acoustics, modeled the human vocal tract. SPASM produced a naturalness of sound and a level of control unavailable with any other voice synthesis technique.
The NeXTstep development environment and the Motorola DSP56001 digital signal processor included with every NeXT computer, made great music, speech, and signal processing research and teaching tools.
The contact was:
Dr. Perry Cook
Research Associate
prc@ccrma.stanford.edu, (415) 723-4971